【Nutanix UUIDエクスプローラーを作ってみよう】REST API 結果を Elasticsearch へ
<【Nutanix Advent Calendar 2021】 6日目の記事です!>
Nutanix Advent Calendar 2021 - Adventar
【Nutanix UUIDエクスプローラーを作ってみよう】シリーズ
・REST APIしてみる
・REST API 結果を Elasticsearch へ イマココ
・Elasticsearch から Flask
・Flask表示までのまとめ

なんで、Elasticsearch?
特に深い理由はなく、過去にさわったことあるのでDB感覚で使って、Kibanaで検索をGUIで体験していきます
Elasticsearch コンテナの準備
REST API で Nutanixクラスタから VMリストを取得できたので、Elasticsearch に必要な情報だけを色々と検索して取り出しやすくしてみたいと思います
まずは、Elasticsearch と Kibana を Dockerコンテナで準備
Elasticsearch の Dockerhub を眺めてみて、新しそうな、7.14.2 を使用してみます
python環境分も含めて「docker-compose」してみます
まずは、Python環境用のDockerコンテナを再作成
Elasticsearchモジュールを追加します
dockerfile
FROM python:3.9.9-slim RUN apt update -y RUN apt install -y curl RUN pip install -U pip RUN pip install jupyterlab RUN pip install elasticsearch #RUN apt install -y netcat WORKDIR /home # execute jpyterlab CMD ["jupyter", "lab", "--ip=0.0.0.0", "--allow-root", "--LabApp.token=''"]
それから、Elasticsearch と Kibana も含めて
docker-compose
version: '3.7' services: es01: image: elasticsearch:7.14.2 container_name: elasticsearch environment: - discovery.type=single-node ports: - 9200:9200 - 9300:9300 volumes: - ./elastic/es-data:/usr/share/elasticsearch/data:z networks: - elastic kibana: image: kibana:7.14.2 container_name: kibana ports: - 5601:5601 networks: - elastic python: build: context: ./python dockerfile: Dockerfile container_name: python ports: - 1234:8888 - 5678:5000 volumes: - ./python/app:/home/app:z networks: - elastic networks: elastic: driver: bridge
Elasticsearchのデータをローカルに貯める用のマウントをつくっておく
→ elasic/es-data
現在のディレクトリ構造
. ├── docker-compose.yml ├── elastic │ └── es-data └── python ├── app │ ├── api-elastic.ipynb └── dockerfile
からの、コンテナ起動
ここまでで Elasticsearch / Kibana の下準備完了
Python から Elasticsearch へ
ここから Pythonコンテナ環境から で Elasticsearch へデータ転送部分を作成
Elasticsearchへの接続テスト
コンテナ環境なので、Elasticsearch へのホスト指定は「elasticsearch:9200」でOK
Elasticsearch内のインデックス情報が取得できます
from elasticsearch import Elasticsearch es = Elasticsearch('elasticsearch:9200') indices = es.cat.indices(index='*', h='index').splitlines() # index一覧を表示 indices

インデックスの作成
# 現状の index確認にして、存在してなければ作成 index_name = 'vm_list' if index_name not in indices: es.indices.create(index=index_name)
VMリストを投入
前回の記事で取得できていた REST APIの結果を格納した変数「response」を
VMごと(Entity)にとりだして、Elasticsearch の 1ドキュメントとして投入します
(VMが10個なら10レコードできるイメージ)
from elasticsearch import helpers from datetime import datetime import json # REST API結果を分解 res_vm = response.json() # クラスタ名取得 cluster_name = res_vms['entities'][0]['spec']['cluster_reference']['name'] # 時間も一緒に投入 timestamp = datetime.utcnow() # REST API取得結果から entitiesだけを抜き出して、配列で格納 # VMごとの _docになり検索しやすい actions = [] for entity in res_vms['entities']: entity['timestamp'] = timestamp entity['cluster_name'] = cluster_name actions.append({'_index':index_name, '_source':entity}) # Elastcisearchへ投入 ※Waringは無視してOK reaction = helpers.bulk(es, actions)
ここまでエラーなく進めば、うまいこといってるはずです
Elasticsearch から返り値と、投入したVM数を表示して確認
# 投入したVM数を表示 reaction, len(actions)

Kibana で可視化
ここからは Kibana を使って、可視化してみます
「localhost:5601」へブラウザでアクセス
Python で作成したインデックスを確認
「vm_list」のインデックスが作られてたら開始します

Index Patternsをとにかく作成

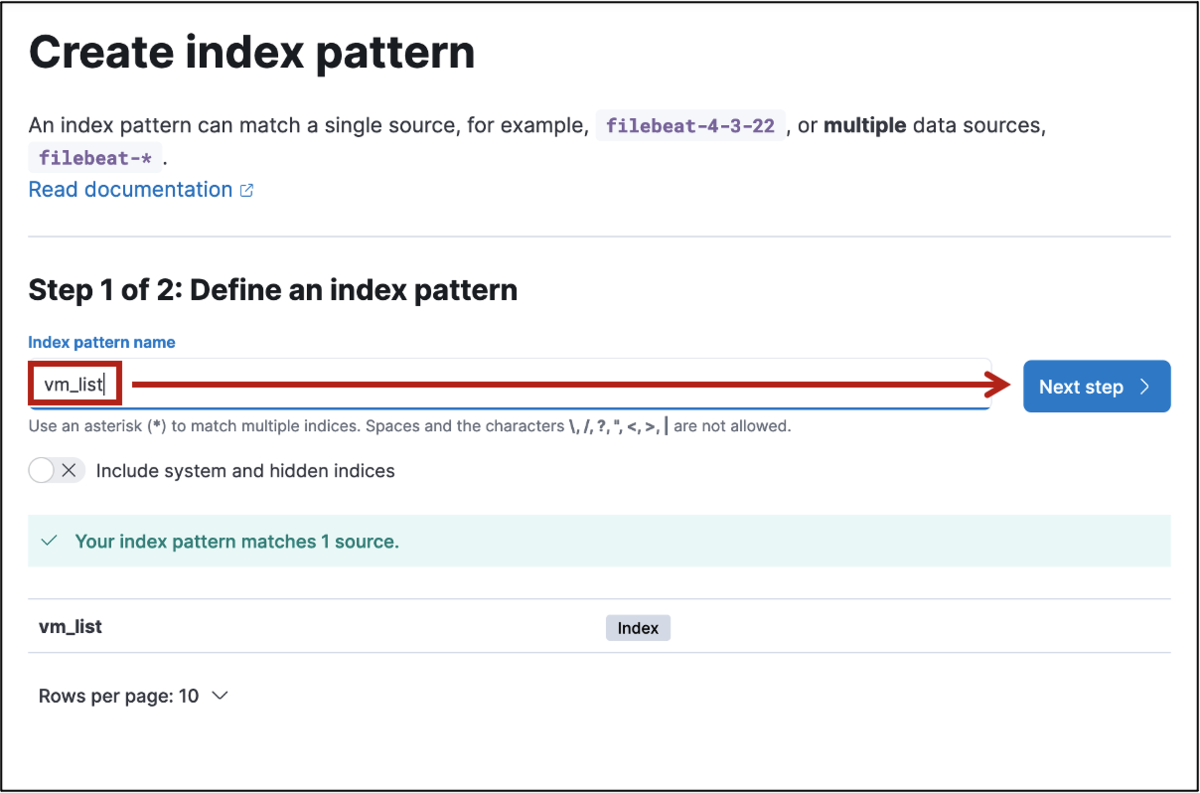

≡メニューから Discover を確認して、なんらかデータはいってれば、Kibana の準備は完了です

「spec.name」と「metadata.uuid」を Add field as column してやることで、表示 VM名と uuid のシンプルな表示にしてやることができます
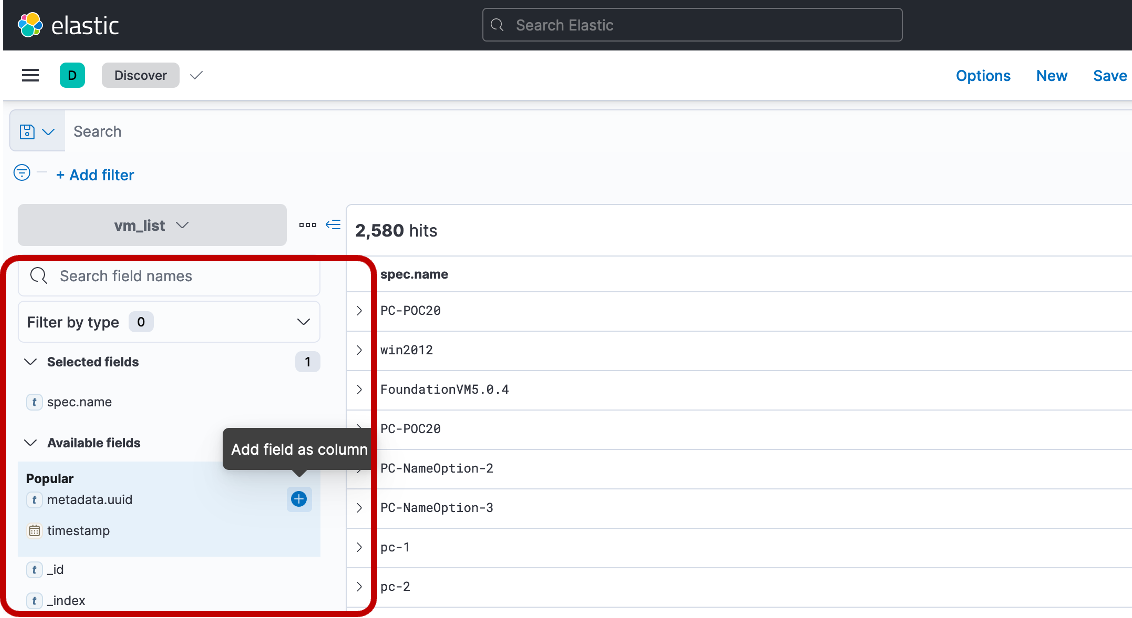
これで、Kibana上で VM名 と uuid だけが表示されるので

VM名 とかで検索したらサクッと uuid が判明します
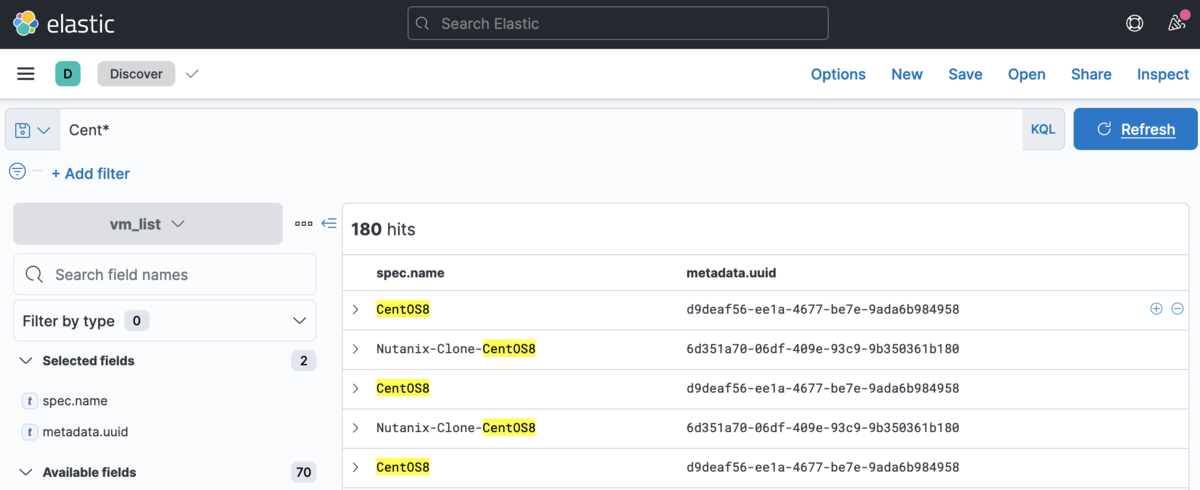
と、まぁこれだけだとたんなる Elasticsearch 講座に進んでしまいそうなので、ElasticsearchをDBのように使いつつ、ここからオリジナルGUIを自作していきたいと思います
次回は、Flask編につづく!
【Nutanix UUIDエクスプローラーを作ってみよう】REST APIしてみる
【Nutanix Advent Calendar 2021】 2日目の記事です!
Nutanix で 何ごとか調査するときには往々にして uuid をキーにして調査することが多いです。
uuid と一言で言ってみても、VM の uuid やら Volume Group (Volumes)の uuid やらあれやこれや調べる必要がでてきます
都度都度、ssh して ncli、acli、、、、結構メンドウです
そんなメンドウごとをGUIで簡単にできないか立ち向かってみます
開発環境は、少し前にチャレンジした「お手軽開発環境(Docker, Jupyter, VScode)」を駆使していきます
過去の記事↓
おてがる開発環境をつくろう カテゴリーの記事一覧 - konchangakita
今回は、初歩の初歩、Nutanixクラスタから REST API で情報取得するところからスタート
【Nutanix UUIDエクスプローラーを作ってみよう】シリーズ
・REST APIしてみる イマココ
・REST API 結果を Elasticsearch へ
・Elasticsearch から Flask
・Flask表示までのまとめ
開発環境を作る
Python 開発環境としては、Dockerhub を眺めて
https://hub.docker.com/_/python
「python3.9.9-slim」
を使うことにします
python 開発環境用のコンテナイメージをこんな感じで作成
ゆくゆくのことを考えて、今回は docker compose も使って環境を作っていきます
Dockerfile
FROM python:3.9.7-slim RUN apt update -y RUN pip install -U pip RUN pip install jupyterlab WORKDIR /home # execute jpyterlab CMD ["jupyter", "lab", "--ip=0.0.0.0", "--allow-root", "--LabApp.token=''"]
docker-compose
version: '3.7' services: python: build: context: ./python3.9.7 dockerfile: Dockerfile container_name: python ports: - 1234:8888 - 5678:5000 volumes: - ./python3.9.7/app:/home/app:z networks: - elastic networks: elastic: driver: bridge
ディレクトリ構造
├── python3.9.7 │ ├── dockerfile │ └── app/ └── docker-compose
あとはこれを実行してみるだけ
とはいっても、コマンドラインで 「docker-compose up -d」は必要なく
VS Code なら docker-composeファイルを右クリックして、「Compose Up」してやるだけです

めちゃ簡単
コンテナ状況をコマンドラインでも確認してみると
ちゃんとポートフォワーディングもしてくれて立ち上がってます
% docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 254f1f0e45c5 hack21-uuid-explorer_python "jupyter lab --ip=0.…" 12 seconds ago Up 11 seconds 0.0.0.0:5678->5000/tcp, 0.0.0.0:1234->8888/tcp python
これで、Jupyter Lab が起動しているはずなので、ブラウザから「localhost:1234」にアクセスしてみます

お手軽環境よろしく、ここからは notebook で python 開発を進めていきます
REST API 認証部分を作る
Python で REST API の第一歩の認証的なところは、Nutanix.dev参照します
API REFENCE には PRISM v2.0 と PRISM v3 が存在してます

PRISM v3 の Authentication を参照して、Nutanixクラスタとの接続・認証部分を書いていきます
import urllib3 import requests import json from base64 import b64encode urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning) ######################### # Cluster情報を入力 ######################### prism_ip = '10.xxx.xx.xxx' prism_user = 'admin' prism_pass = 'nutanix/4u' # authentication # 参考 https://www.nutanix.dev/reference/prism_central/v3/authentication request_url = 'https://' + prism_ip + ':9440/api/nutanix/v3/vms/list' encoded_credentials = b64encode(bytes(f'{prism_user}:{prism_pass}', encoding='ascii')).decode('ascii') auth_header = f'Basic {encoded_credentials}' headers = {'Accept': 'application/json', 'Content-Type': 'application/json', 'Authorization': f'{auth_header}', 'cache-control': 'no-cache'}
REST API で VMリストを取得する
REST API についてはNutanix Prismクラスタの REST API エクスプローラで参照します

vms の VMのリストを取得することにします

POST でリクエストするパラメータに関しては
Data Type の Model をクリックすることで、パラメータの意味、必須パラメータなのか、オプションなのかなど確認できます
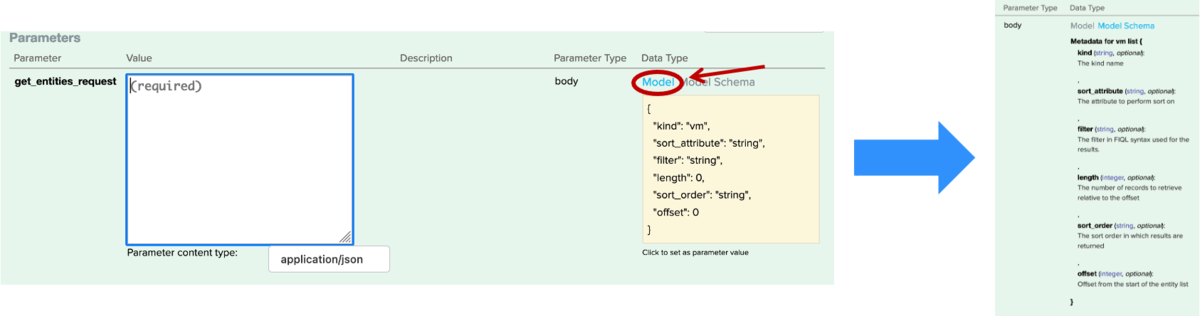
パラメータとして
「kind : vm」
「length : 256」
だけを指定してみます
payload = '{"kind":"vm", "length":256}' response = requests.request('post', request_url, data=payload, headers=headers, verify=False, timeout=3.5) response
実行してみると「200」が返ってきて、いけてそうです

レスポンス結果は、json形式にしてやることで内容を確認できます
response.json()

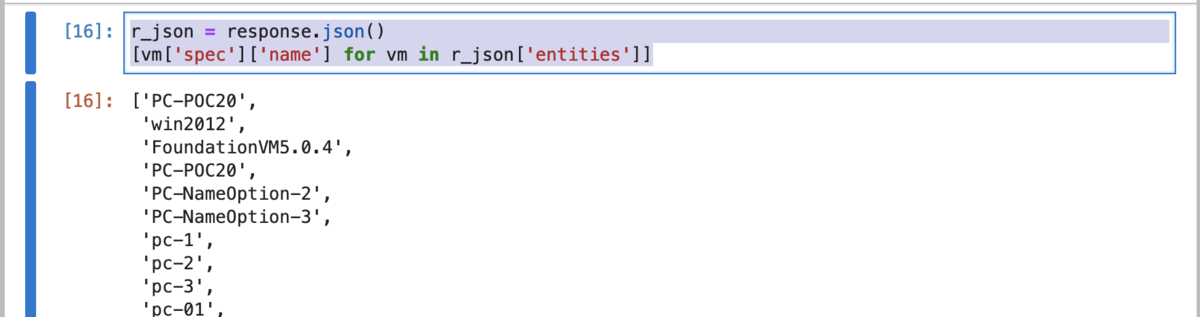
'entities' に各VMの情報が入っているので、試しにVM名だけを取り出してみます
r_json = response.json() [vm['spec']['name'] for vm in r_json['entities']]
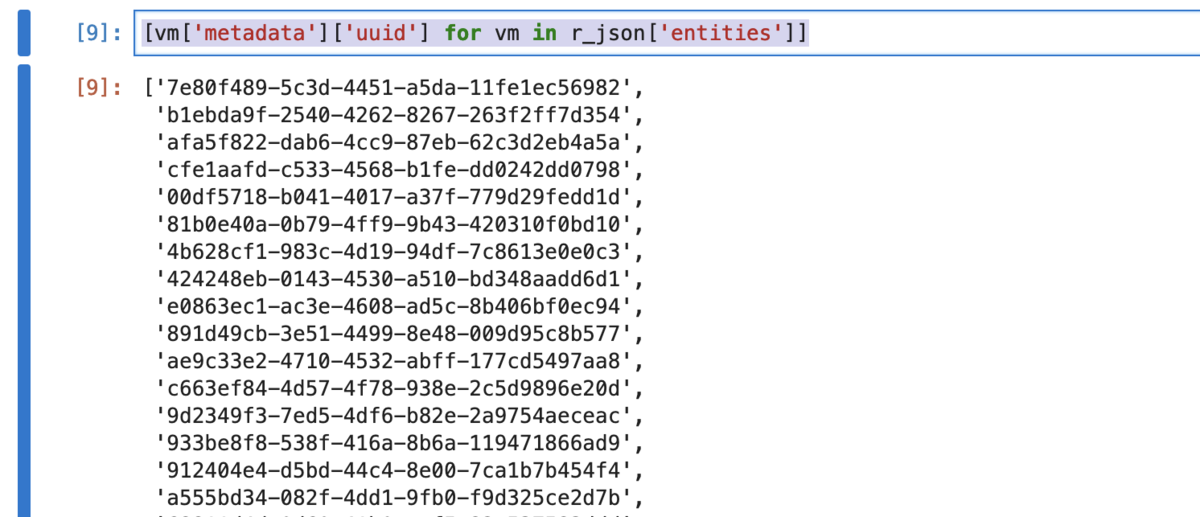
uuid を取り出したい場合は、こう
[vm['metadata']['uuid'] for vm in r_json['entities']]
Nutanix REST API の第一歩目ははなんとかクリア
Elasticsearch編につづく!
VS Code で Azure CLI してみる
せっかく Azure のお勉強をしはじめたので、Azure Cloud Shell のコマンドを VS Code から実行できる環境を作ってみたいとみたいと思います
Azure Cloud Shell は、通常 Azure ポータル上で実行する CLI のやつです

Windows に Azure CLI をインストールする(Windows版)
まずは VS Code を使う マシン に Azure CLI をインストールします
MS公式のココの手順に沿っていきます
Windows での Azure CLI のインストール | Microsoft Docs
1.まずはインストーラーをダウンロードして


3.Windows で Azure CLI の実行
これで Azure CLI が実行できる環境が整ったので、コマンド実行を試してみましょう
Windows Terminal(PowerShellでよい)から Azure ログイン
PS > az login
するとコマンドを実行すると、ブラウザが立ち上がって Azure のアカウントを求められます

↓ ↓ ↓
ログインすると、Azure CLI ドキュメントページにリダイレクトされつつ
Azure コマンド ライン インターフェイス (CLI) - 概要 | Microsoft Docs
コマンドライン上でもログイン情報がつらつらと出てきます

サブスクリプションが複数ある場合、まず切り替えてみます
サブスクリプションを確認して
> az account list --output table

切り替える
az account set --subscription "サブスクリプション名"
これで、Windowsローカルマシンから Azure CLI が実行できる環境が準備できました
続いて、VS Code から Azure CLI していきましょ
VS Code で Azure CLI
VS Code に拡張機能を追加していくことで、Azureアカウントと連携して、VS Code上から Azure CLI が実行できるようになります
Azure アカウント連携
まずは、VS Code に「Azure Account」の拡張機能をインストール

これで、Auzre へのログイン、サブスクリプションの切り替えはすべてGUIで行う事ができます
コマンドパレット [F1] - [Azure Sign in] すると PowerShell で az login を実行したのと同じ感じでブラウザが立ち上がりログインするアカウントを選択します
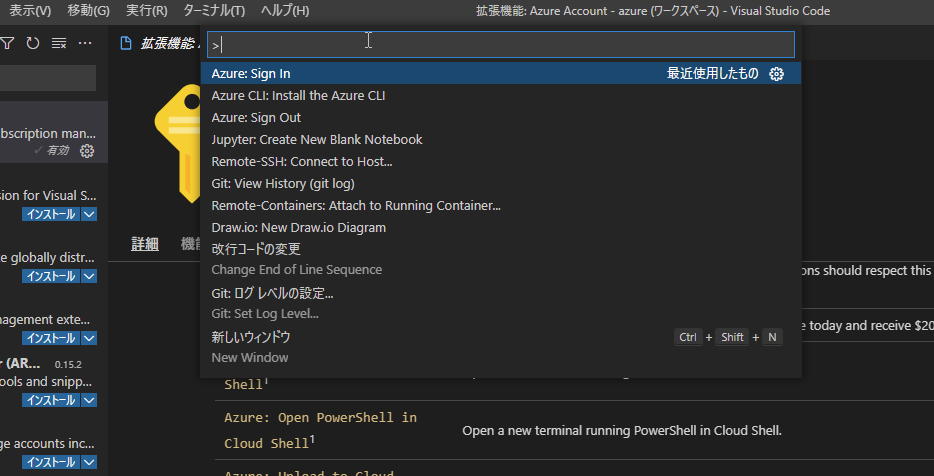
サブスクリプションの切り替えは、アカウント選択後、画面下の 「Azure: アカウント名」をクリックするとサブスクリプションを選択できます。楽チン!
Azure CLI拡張機能
VS Code 自体に PowerShell ターミナルがついているので、もちろんそこで「az ~~」って、コマンドを打ち込んでも良いわけですが、せっかくの高機能エディタなので便利に使ってみます
「Azure CLI Tools」拡張機能をインストールします

新しくファイルを開いて、何か Azure cli コマンドを記述して「Azure CLI scrapbook」形式で保存します

そうするとコマンドパレットに Azure CLI メニューが 増えています
・Azure CLI: Run Line in Terminal - ターミナル内で実行して表示
・Azure CLI: Run Line in Editor - 別画面のエディタに実行結果を表示
・Azure CLI: Toggle Live Query - ちょっとよくわかんない
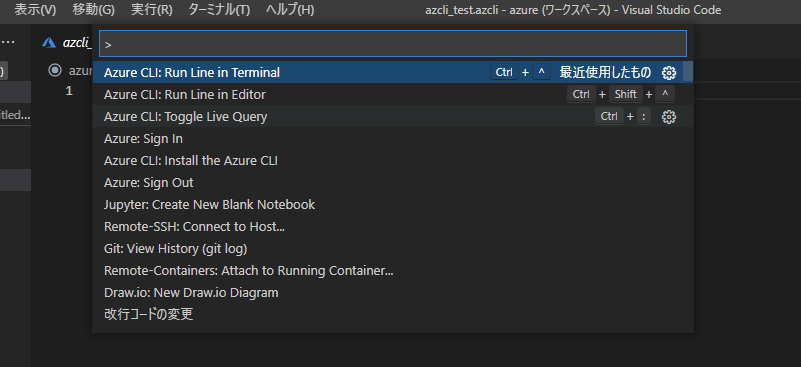
はじめは、コマンドラインで直打ちでええやんと思ってましたが、コピペとか考えたり、エディタに出力結果が出るのって結構良いです
さいごに
まだまだ Azure Cloud Shell はなんだかメンドクサイイメージあったのですが、これならいろいろ試しながら使えるので捗りそう
Azure Solutions Architect Expert(AZ-303/AZ-304)お勉強メモ

これだけ覚えてたら、勝てる、、、わけもなく
こんだけ知らなかったってこと
裏を返すと、ここに書いてることは当然理解して周辺情報を説明できることは必須desu!
では、いってみよー
自分の備忘録用 AZ-303 / AZ-304 対策ごちゃまぜメモ
■ログ/監視 関連
・アクティビティログ
保存期間 90日
リソースデプロイメントログ
・Azure Monitor
Insights: Application, Container, VM, Monitoring Solution
Visualize: Dashboards, Views, Power BI, Workbooks
Analyze: Metric Analytics, Log Analytics
Respond: Alerts, Auto scale
Integrate: Logic Apps, Export APIs
・Azure Performance Diagnostics
Azure Monitor エージェント
VM のメトリックとログを監視(Azure VMのみ、Log Analyticsだと他にもいろいろ)
■ポリシー
・Azure ポリシー
コンプライアンス評価
Azure RBAC は、さまざまなスコープでのユーザー操作の管理にあります。アクションの制御が必要な場合は、Azure RBAC が使用に適したツールになります。 あるユーザーがアクションを実行するためのアクセス権を持っていても、結果としてリソースが準拠していない場合、その作成や更新は Azure Policy によってブロックされます。
・仮想マシン スケール セット
同じ VM のセットをデプロイして管理するために使用できる Azure コンピューティング リソース
水平スケーリング:VMの増減
垂直スケーリング:メモリ、CPU 電源、ディスク、VM を再起動する必要がある
スケジュールスケーリング、自動スケーリング(CPU、ネットワーク、ディスクIO/キュー)
・スケールセットの設定方法
1.sysprep
2.CLIで一般化
3.スケールセットを作成
■開発向け
・Azure Batch
何十、何百、何千もの VM にスケーリング
1.コンピューティング VM のプールを自動的に開始する。
2.アプリケーションとステージング データをインストールする。
3.必要なすべてのタスクが含まれるジョブを実行する。
4.エラーを識別する。
5.作業を再度キューに入れる。
6.作業が完了したらプールをスケールダウンする。
・App Service
エンタープライズ レベルの Web アプリ、モバイル アプリ、API アプリを、すばやくビルド、デプロイ、スケーリング
App Service プランによって、ホストに利用されるハードウェアの量が決まる。ハードウェアが専用か共有か、予約されるメモリ量
・Webjob
再試行可能、Web アプリケーション、モバイル バックエンド、RESTful API のためのクラウドベースのホスティング サービス
・Azure Functions
コード実行に特化
従量課金サービス プラン/Azure App Service プラン
・Azure Logic Apps(開発者向け)
ワークフロー、GUI、デザイン優先
トリガー(ポーリング、プッシュ、繰り返し、手動)
Azure ロジックアプリを作成できる権限・役割は?
- contributor, Logic App Contributor
・Power Automate(ユーザ向け)
GUI
・Azure Resource Manager
宣言型のオートメーション:必要なリソースが "何" かは定義するが、それを作成する "方法" は定義しない。
必須プロパティ:name type apiVersion location properties
依存リソースの定義 depends on
・Azure Data Factory パイプライン
1 つのタスクを連携して実行するアクティビティの論理的なグループ
マッピング データ フロー:GUIでデータ変換
・Azure Data Lake Analytics
オンデマンド分析ジョブ、ビッグデータの処理
■ネットワーク
・VMのPerformance Diagnostics
ネットワークトレースキャプチャ
・ピアリング
Azure 仮想ネットワーク同士をシームレスに接続
接続において、見かけ上 1 つのネットワークとして機能
・VPN
サイト間、ポイント対サイト、ネットワーク対ネットワーク" 間
ポリシーベースVPN:IKEv1、静的ルーティング
ルートベースの VPN:IKEv2、動的ルーティング、オンプレデバイス用の接続方法として推奨、仮想ネットワーク間、ポイント対サイト、マルチサイト接続、ExpressRoute ゲートウェイとの共存
必要なリソース:仮想ネットワーク、GatewaySubnet、仮想/ローカル ネットワークゲートウェイ、接続
Active/Standby(デフォルト)
・EXPRESS ROUTE
99.95%
レイヤ3接続(アドレスレベル)
BGP
プライベートピアリング/MSピアリング
帯域(50M - 10G 後で縮小できない)
仮想ネットワーク(MAX 10個)
- Microsoft Office 365
- Microsoft Dynamics 365
- Azure Virtual Machines などの Azure コンピューティング サービス
- Azure Cosmos DB や Azure Storage などの Azure クラウド サービス
ExpressRoute Direct(100G)
・Traffic Manager
クライアントを特定のサービス エンドポイントの IP アドレスへ誘導
重み付けルーティング/パフォーマンス ルーティング/地理的ルーティング
可用性の向上
・Azure Load Balancer
分散モード[セッション永続化]
- 5タプルハッシュ(デフォルト):送信元IP/ポート、送信先IP/ポート、プロトコル
- 接続元 IP アフィニティ:送信元IP/ポートのみ(リモート デスクトップ ゲートウェイはこっちのみ対応)
可用性セット(99.95%):物理HWを分ける
可用性ゾーン(99.99%):DCを分ける(同一リージョン)
・Application Gateway
ラウンドロビン、WAF、L7 LB、SSLオフロード
・API Management
仮想ネットワーク対応は Premium
■Azure SQL
可用性99.99%
・クエリパフォーマンスインサイト
時間のかかるクエリ特定
・エラスティックプール
ゾーン冗長:Premium サービス層の Availability Zones のサポート
■セキュリティ
・Key Vaultのアクセスポリシー
特定VMからのみシークレット登録させるには、アクセスポリシー
■ストレージ
・blob
クール:30日
アーカイブ:最低180日間保管
・Storage ATP(Advanced Threat Protection)
・Azure File sync
オンプレミスの Windows Server またはクラウド VM に多数の Azure ファイル共有をキャッシュできるサービスです
・AzCopy
Blogにup/down、ストレージアカウント間のBlob、Azure Files, AWS S3/GCP/Azure Stack
承認方法:Azure AD, SASトークン
・Azure Defender for Storage(Storage Advanced Threat Protection)
Blob と Files の脅威を検出
・Azure Import / Export
Azure データセンターにディスク ドライブを送付することで、Azure Blob Storage と Azure Files に大量のデータを安全にインポート
■Azureへの移行
評価、移行、最適化、監視
評価:検出、再ホスト、リファクタ、再設計、再構築、置換
移行:デプロイ、移行、オンプレ停止
最適化:運用コスト分析
監視:
・Azure Migrate
無償、評価
コレクターVM:検出、vCenter連携、オンプレVMの依存関係を知るにはAgentが必要
Azureポータルで評価を作成
レプリケートは100台づつ
・Azureハイブリッド特典(Azure Hybrid Benefit)
Windows Server 、 SQL Server、 RedHat 、 SUSE Linux
オンプレミスと Azure 間での 180 日間の二重使用権
■バックアップ・DR
・Azureバックアップ
オンプレはWindowsのみ、Azure VM/Files/SQL/SAP
Backupエージェント(MARS)
■Azure Site Recovery
VPN必須
Hyper-Vホストの登録
1.コンテナー登録キー(Vault registration key)ダウンロード
2.ASR Providerインストール
3.サーバ登録
4.レプリケーションポリシー設定
5.有効にする
オンプレミス Hyper-V VM から Azure へのディザスター リカバリーのサポート マトリックス
https://docs.microsoft.com/ja-jp/azure/site-recovery/hyper-v-azure-support-matrix
・OSディスク
第 1 世代の VM では最大 2,048 GB
第 2 世代の VM では最大 4,095 GB
データディスク:MAX 4TB
集中管理
オンプレミスの仮想マシンのレプリケーション
Azure 仮想マシンのレプリケーション
フェールオーバーの間のアプリの整合性
Recovery Services コンテナー:フェールオーバー実行時のVMが格納される
資格情報:仮想マシン共同作成者 ロールと Site Recovery 共同作成者 ロールが必要
・アプリケーション レプリケーション
ワンクリック フェールオーバー、スクリプト統合、ネットワーク マッピング
・Site Recovery を使ったVMの移行
■Azure AD
・Azure AD Connect Health
電子メール経由のアラート
・マネージドID
Azure AD認証をサポートするリソースに接続するときに使用する ID をアプリケーションに提供
開発者が安全に資格情報を格納できる Azure キー コンテナーなどのリソースにアクセスしたり、ストレージ アカウントにアクセスしたりできる
システム割当:サービス インスタンスに対して直接マネージド ID を有効、インスタンスと一緒に削除される
ユーザ割当:複数のインスタンスに適用することができる
・ハイブリッドID
パスワードハッシュ同期(PHS)、パススルー同期(PTA)、フェデレーション(AD FS)
・Azure AD Connect
実装する権限:オンプレAD:Enterprise Admins、Azure AD:Global Admin
・fault domain x update domain = サーバ数
・Azure Active Directory シームレス シングル サインオン
Azure AD Connect サーバー
サポートされている Azure AD Connect トポロジ
ドメイン管理者の資格情報がセットアップ
発信 HTTP プロキシを使用している場合は、この URL (autologon.microsoftazuread-sso.com)書いとけ
・B2C
企業-カスタマー間(B2C)のIDが提供される
OpenID Connect、OAuth 2.0、SAMLなど
・アプリケーション登録(Azure AD app registration)
アプリケーション登録して、ユーザ認証
・条件付きアクセス(conditional access policy)
ユーザー、デバイス、アプリケーション
ネームド ロケーション:名前 と IP 範囲を指定する
■AKS
Azure のマネージド Kubernetes
自動スケーリング、ストレージオプション
ノード使った分、お支払い
IPアドレスのオプション有り
・コンテナレジストリ作成
az acr create --resource-group myResourceGroup --name
コンテナレジストリのURLは、「
docker push
■その他
・Azure ブループリント(試験では青写真)
リージョン間コピーされる、
・暗号化
決定論的(determine):等値のルックアップ、結合、グループ化を実行可能
ランダム化:できない
・HTTP を使用してトークンを取得する
使用するアドレス:169.254.169.254
https://docs.microsoft.com/ja-jp/azure/active-directory/managed-identities-azure-resources/how-to-use-vm-token
・Azure Bastion
Azure Bastion は、ブラウザーと Azure portal を使用して仮想マシンに接続できるようにするサービス
仮想マシン IP の一般公開を制限する
共有外部IPアドレスを介してRDP
・Privileged Identity Management(特権ID管理)
アクセスレビユー作成ができる
最後に
繰り返しになるのですが、MS Learnは素晴らしいコンテンツなので、勉強の入り口としてはちょうどよいです
あとは、気になったワードは MS Docs を読んで、理解して、関連知識と、Azureポータルで操作マスターしてれば間違いない(はず)
Azure の資格試験にチャレンジ
必要にせまられたわけでもなく、Azure を仕事で使っているわけでもないのですが、なんとなくブログにネタにしようってレベルでチャレンジ
これまでの Azure歴は、Jetson Nano からの Azure IoT で エッジAI/IoT 的なことやったり、Nutanix KPS で Blob になんか飛ばしたり、Cognitiveのハンズオンしたりくらいのニッチなとこしか触ったことない。。。
インスタンス立てたり、Azure ADなんてもってのほかってレベルからお勉強をスタートしてみました
そしたらあっさり一回目試験落ちてしまったので、改めて自戒の念もこめてアウトプット
Azureの資格試験の種類
とりあえず上級(Expert)といわれるものだけをピックアップしてみましょう
今年は E資格も取得したので調子のってみる
2021年7月時点では、Azure 関連の Expert はレベル 2つだけの模様
Azure Solutions Architect Expert
Azure Fundamentals や Azure Administrator Associate の上位になるみたいですね
DevOps Engineer Expert
こちらは Developer 系の上位資格です
ターゲットは Azure Solutions Architect Expert
Azure Solutions Architect Expert にむけて
この資格の認定をうけるには2つの試験をうける必要があります
各試験とも 21,103円、落ちるとまぁまぁなダメージ
AZ-303: Microsoft Azure Architect Technologies
試験範囲: Azure インフラストラクチャの実装と監視、管理およびセキュリティソリューションの実装、アプリケーションのソリューションの実装、およびデータプラットフォームの実装と管理
AZ-304: Microsoft Azure Architect Design
試験範囲: 監視の設計、 アイデンティティとセキュリティの設計、 データストレージの設計、 ビジネス継続性の設計、 インフラストラクチャの設計
違いとしては、テクノロジーとデザインということで、テクノロジーはより構築・設定、デザインは提案みたいな感じ?
受験方法は、ITベンダー資格でよくある Peason Vue の会場かオンラインから選択です
勉強方法どうするか
勉強方法としては、MS Learn のコースが用意されているので、一通りやっておきます
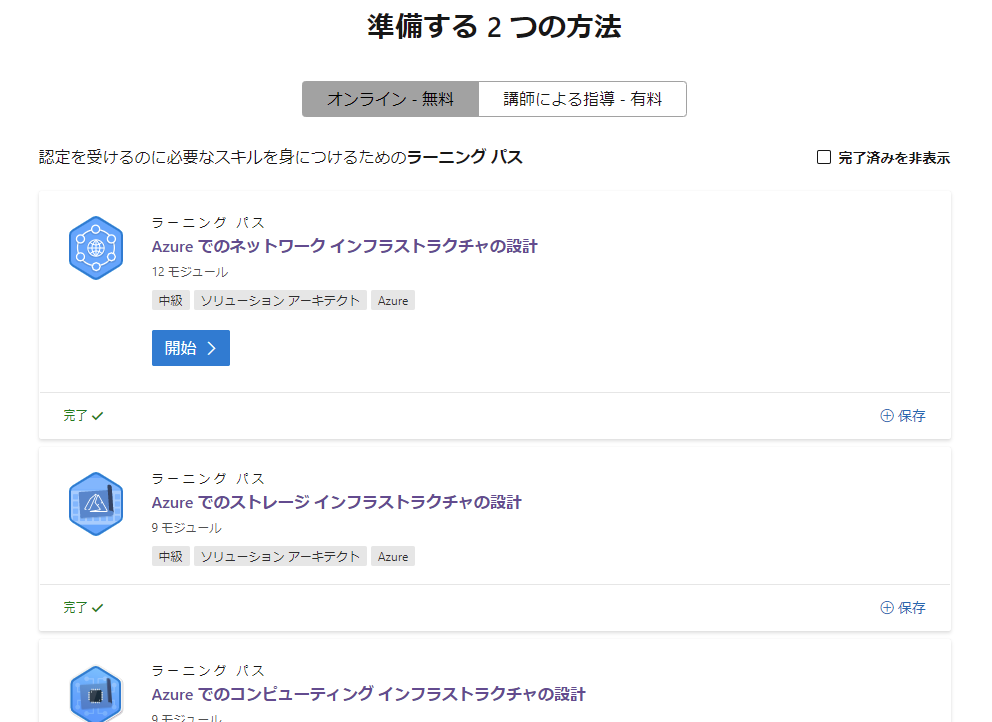
Azure Solutions Architect Expert 用にラーニングパス(複数モジュールの塊)が 9個、約56時間分用意されています
MS Learn はめっちゃよくできたコンテンツで、試験にもでてきそうなサンプル構成例を用いながら、実際の Azure ポータルの環境を使ってハンズオンできたりもするので、理解に役立ちます
(ハンズオンするためには、無償版でいいのでAuzreアカウントを作っておきましょう)
この他にもちょっと分からない単語がでてきても、そこは天下のMSさん「Azure ○○○」とかでググったらすごく分かりやすい MS Docs が見つかります
AZ-303 / AZ-304 の試験対策
推奨されている MS Learn コースは AZ-303/AZ-304 は共通なので、まずはじっくりと MS Learn をこなしていきましょう
ただ、MS Learn はコンテンツがよく出来すぎていて、時間かけた分だけ理解したつもりになってしまいがちという罠があります、、、、
単語の理解があやしいな、と思ったら何回でも繰り返しチャレンジしておくとよいです
Azure Solutions Architect Expert 用にラーニングパスでは、Azure AD に関するコースが全然入っていなかったので追加でやっておくとよいかも
こまったときの Udemy
ここのとこ新しいことにチャレンジする時にお世話になっているUdemy(https://www.udemy.com/)で AZ-303 / AZ-304 を検索してみると、英語のコースが見つかりました
せっかくなので、がっつり勉強すべくコース内容が濃そうな(12.5時間分)AZ-303用のこちらのコースも購入してみました
AZ-303 Azure Architecture Technologies Exam Prep 2021 | Udemy
ひととおりやってみましたが、AZ-303用なので試験にでてきそうな操作方法等重点的な内容で試験向けポイント解説なんかもあったので時間が許す限りじっくり見てみてもよいかも、でも結局試験を日本語でうけるならばちょっとハードル高いかも。。。。
Udemy には他にも Azure 関連で日本語のはすくないっすね
試験に向けて
MS Learn は思った以上に時間を使いました。知らない(初心者すぎて)初めてコンテンツだと目安時間より、多く時間がかかりやってるうちに他の内容忘れてくという
MS Learn だけで、だいたい2週間分くらいがっつりやったかな
【おてがる開発環境をつくろう】VS Code あれもこれもエクステンション

VS Codeは、初期状態からエクスプローラ機能、ターミナルが使えて便利ですが、拡張機能(エクステンション)を導入することで真価を発揮します
エクステンションは数多くあるので、奥が深いです
とりあえず自分が使った範囲で、Python、Jupyter、Dockerを扱う環境で便利だったエクステンションをご紹介
【おてがる開発環境をつくろう】
1.まずは Docker Desktop インストール
2.Docker であそぶ Python 入りのコンテナつくる
3.コンテナで Jupyter Lab 環境
4.さいきょうのえでぃた VS Code
5.VS Code はあれもこれもエクステンション ←今ココ
とにかく便利なエクステンション(とりあえず入れておけ)
indent-rainbow:インデントに色をつけて見やすくしれくれます
Trailing Spaces:空白に色をつけて余計な空白の見落としを防ぎます
Material Icon:アイコンをかわいく表示
python:コーディングが楽になる
Jupyter:JupyterをVSCodeで実行
Docker:Docker機能を可視化
Remote Development:VSCodeからSSHして、ローカルかのようにファイル管理できる
indent-rainbow
タブごとに色分けにしてくれて、ぱっと見がわかりやすくなります

Trailing Spaces
無駄な空白を赤くみせつけてくれます

Material Icon
アイコン表示をかわいくしてくれます
python
構文に合わせて色とか変えてくれる
予測変換的なこと(Lint)もしてくます

Docker
コンテナイメージのビルドやコンテナ内のファイルをGUIで扱える
でも実際にファイルをいじるのはこの後の Remote-container の方が便利

Remote Development とにかく超便利
Remote-WSL, Remote-Containers, Remote-SSHの3つセットになっています
これがあるから VS Code はやめられない!
Remote接続して、エクスプローラで操作が可能になり、Remote接続先のファイルを ローカルと同じように VS Code で編集
Teratermさようなら案件
「Ctrl+Shift+P」でコマンドパレットを開き「remote」と入力
接続したい環境を選ぶ
・SSH
・Container
・WSL(使ったことない)



Container 接続


再接続は
一度接続した接続先情報は覚えている 便利!

【おてがる開発環境をつくろう】さいきょうのえでぃた VS Code
ルーキー開発者が最強のえでぃたを装備した
おてがる開発環境シリーズの最後は、「VS Code」です
今までの、Docker、Python、Jupyter 全てにおいて、VS Code で便利に使うことができます
【おてがる開発環境をつくろう】
1.まずは Docker Desktop インストール
2.Docker であそぶ Python 入りのコンテナつくる
3.コンテナで Jupyter Lab 環境
4.さいきょうのえでぃた VS Code ←今ココ
5.VS Code はあれもこれもエクステンション!!
VS Code のオススメな理由
・エディタなので、当然ながら Python との相性は抜群
・ターミナルがついてる
・リモートSSH/コンテナがかなり便利
- パスワードでも、鍵認証でも
- ssh先のファイルを VSCodeエディタで開けるだとっっ!!!
- コンテナ内のエクスプローラも楽ちん
・gitを GUI でも CLI でも
・Azure 機能との連携も豊富
VS Code をインストールしよう
ここからダウンロード
azure.microsoft.com
MS製ですが、もちろん MAC版も用意されています

インストールしたら、VS Code 画面配置でよく使うところをみてみましょう

VS Code の設定は初期のままでも結構いける
昔のエディタは、デフォルトのままでは使い物にならなくて、初期設定から結構いじる必要がありましたが
(主に文字サイズとかショートカットとか)
ちなみに固有のセッティングはここから変更できますが、ほとんどさわったことないです

設定やプラグインなど導入した場合に、自宅用のデスクトップとノートPC、Windows と MAC 間で設定を同期することもできます
プラグイン設定も同期できるのは、超便利

Githubアカウント経由で同期される
この辺はさすが MSさん

ワークスペースを作る
ワークスペースはおおざっぱにいうと、作業フォルダのショートカット集をつくるみたいな感じです
VS Code のエクスプローラをより便利に使いこなす為には、まずはじめにワークスペースを作っておくべき
プロジェクトごとや、やりたいこと別にワークスペースごとに作ってくようなイメージです

ターミナルを開く
「Ctrl + @」でターミナルをトグルできます
また、VS Code の超便利な機能(パート2)として、指定のディレクトリでターミナルを開くってのがあります
プログラミングしていて、このファイルを実行したいって時に
ターミナル開いて、ディレクトリ移動して、実行ってメンドウな経験したことないでしょうか
開きたいファイルやディレクトリを右クリックして、「Open in integrated Terminal」

よく使うショートカットコマンド
Ctrl+@:ターミナルをトグル
Ctrl+Shift+p:コマンドパレットを開く
