【Nutanix UUIDエクスプローラーを作ってみよう】REST API 結果を Elasticsearch へ
<【Nutanix Advent Calendar 2021】 6日目の記事です!>
Nutanix Advent Calendar 2021 - Adventar
【Nutanix UUIDエクスプローラーを作ってみよう】シリーズ
・REST APIしてみる
・REST API 結果を Elasticsearch へ イマココ
・Elasticsearch から Flask
・Flask表示までのまとめ

なんで、Elasticsearch?
特に深い理由はなく、過去にさわったことあるのでDB感覚で使って、Kibanaで検索をGUIで体験していきます
Elasticsearch コンテナの準備
REST API で Nutanixクラスタから VMリストを取得できたので、Elasticsearch に必要な情報だけを色々と検索して取り出しやすくしてみたいと思います
まずは、Elasticsearch と Kibana を Dockerコンテナで準備
Elasticsearch の Dockerhub を眺めてみて、新しそうな、7.14.2 を使用してみます
python環境分も含めて「docker-compose」してみます
まずは、Python環境用のDockerコンテナを再作成
Elasticsearchモジュールを追加します
dockerfile
FROM python:3.9.9-slim RUN apt update -y RUN apt install -y curl RUN pip install -U pip RUN pip install jupyterlab RUN pip install elasticsearch #RUN apt install -y netcat WORKDIR /home # execute jpyterlab CMD ["jupyter", "lab", "--ip=0.0.0.0", "--allow-root", "--LabApp.token=''"]
それから、Elasticsearch と Kibana も含めて
docker-compose
version: '3.7' services: es01: image: elasticsearch:7.14.2 container_name: elasticsearch environment: - discovery.type=single-node ports: - 9200:9200 - 9300:9300 volumes: - ./elastic/es-data:/usr/share/elasticsearch/data:z networks: - elastic kibana: image: kibana:7.14.2 container_name: kibana ports: - 5601:5601 networks: - elastic python: build: context: ./python dockerfile: Dockerfile container_name: python ports: - 1234:8888 - 5678:5000 volumes: - ./python/app:/home/app:z networks: - elastic networks: elastic: driver: bridge
Elasticsearchのデータをローカルに貯める用のマウントをつくっておく
→ elasic/es-data
現在のディレクトリ構造
. ├── docker-compose.yml ├── elastic │ └── es-data └── python ├── app │ ├── api-elastic.ipynb └── dockerfile
からの、コンテナ起動
ここまでで Elasticsearch / Kibana の下準備完了
Python から Elasticsearch へ
ここから Pythonコンテナ環境から で Elasticsearch へデータ転送部分を作成
Elasticsearchへの接続テスト
コンテナ環境なので、Elasticsearch へのホスト指定は「elasticsearch:9200」でOK
Elasticsearch内のインデックス情報が取得できます
from elasticsearch import Elasticsearch es = Elasticsearch('elasticsearch:9200') indices = es.cat.indices(index='*', h='index').splitlines() # index一覧を表示 indices

インデックスの作成
# 現状の index確認にして、存在してなければ作成 index_name = 'vm_list' if index_name not in indices: es.indices.create(index=index_name)
VMリストを投入
前回の記事で取得できていた REST APIの結果を格納した変数「response」を
VMごと(Entity)にとりだして、Elasticsearch の 1ドキュメントとして投入します
(VMが10個なら10レコードできるイメージ)
from elasticsearch import helpers from datetime import datetime import json # REST API結果を分解 res_vm = response.json() # クラスタ名取得 cluster_name = res_vms['entities'][0]['spec']['cluster_reference']['name'] # 時間も一緒に投入 timestamp = datetime.utcnow() # REST API取得結果から entitiesだけを抜き出して、配列で格納 # VMごとの _docになり検索しやすい actions = [] for entity in res_vms['entities']: entity['timestamp'] = timestamp entity['cluster_name'] = cluster_name actions.append({'_index':index_name, '_source':entity}) # Elastcisearchへ投入 ※Waringは無視してOK reaction = helpers.bulk(es, actions)
ここまでエラーなく進めば、うまいこといってるはずです
Elasticsearch から返り値と、投入したVM数を表示して確認
# 投入したVM数を表示 reaction, len(actions)

Kibana で可視化
ここからは Kibana を使って、可視化してみます
「localhost:5601」へブラウザでアクセス
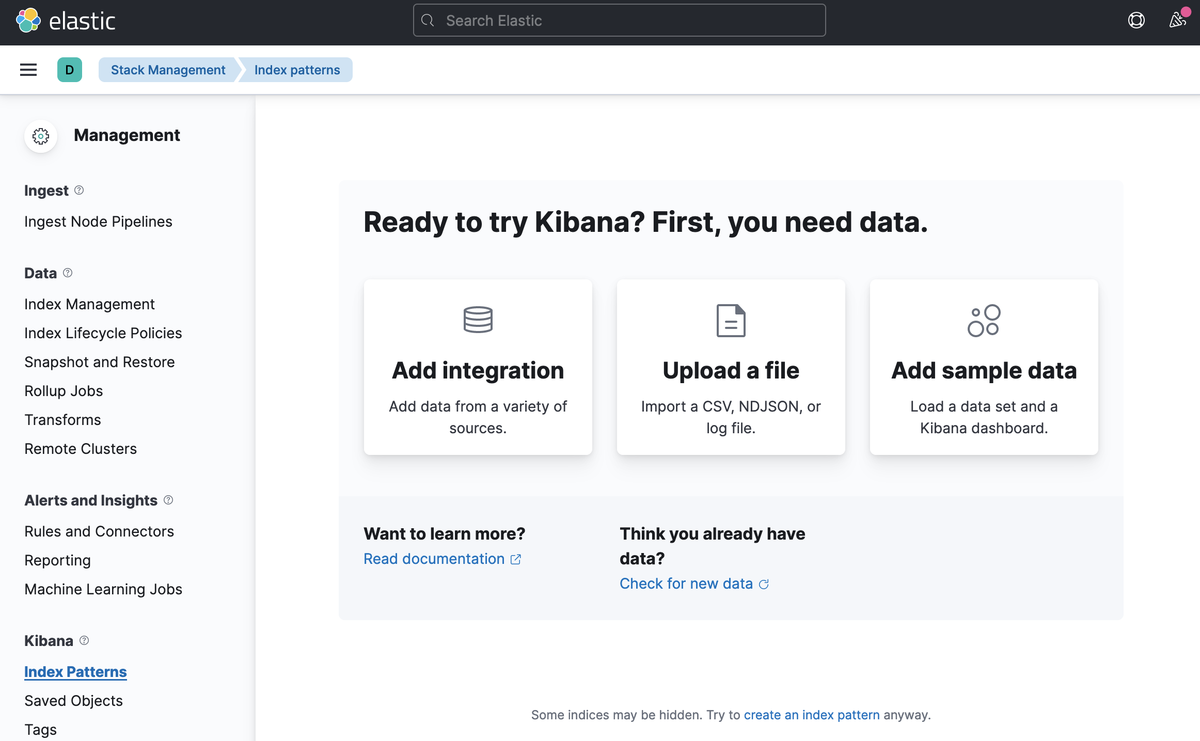
Python で作成したインデックスを確認
「vm_list」のインデックスが作られてたら開始します

Index Patternsをとにかく作成

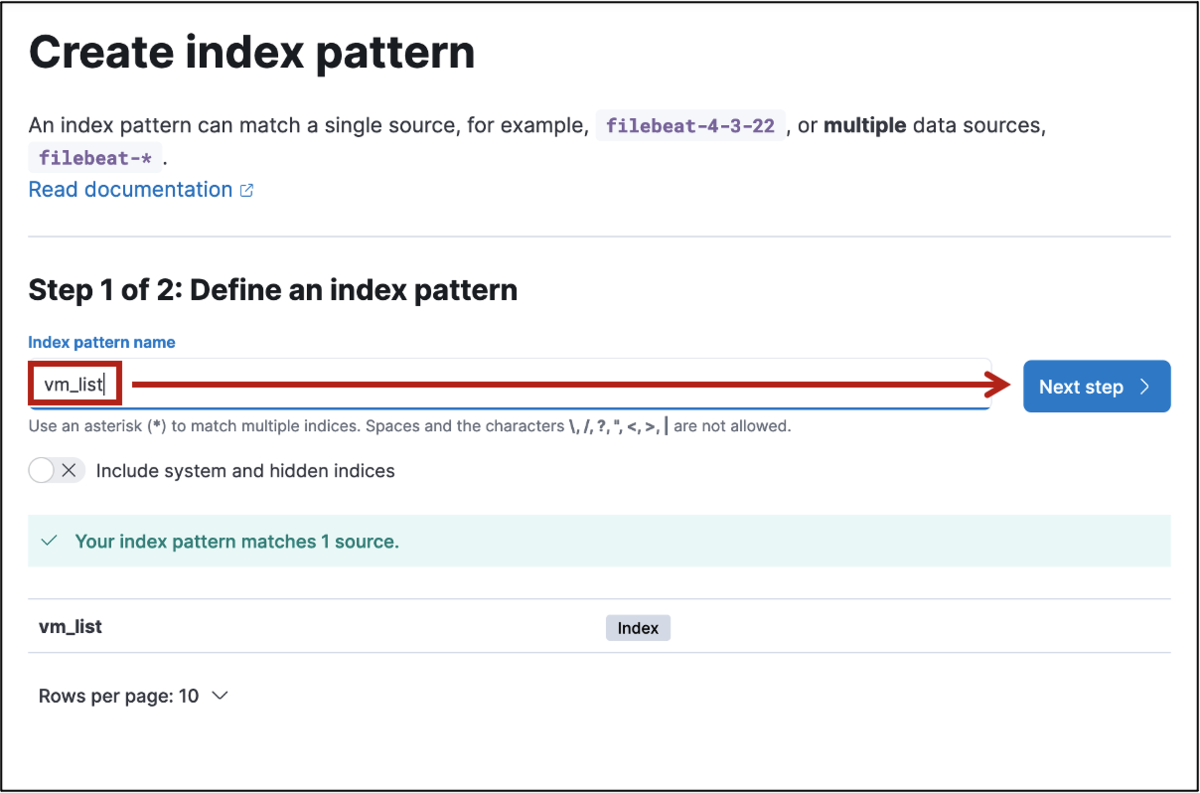

≡メニューから Discover を確認して、なんらかデータはいってれば、Kibana の準備は完了です

「spec.name」と「metadata.uuid」を Add field as column してやることで、表示 VM名と uuid のシンプルな表示にしてやることができます
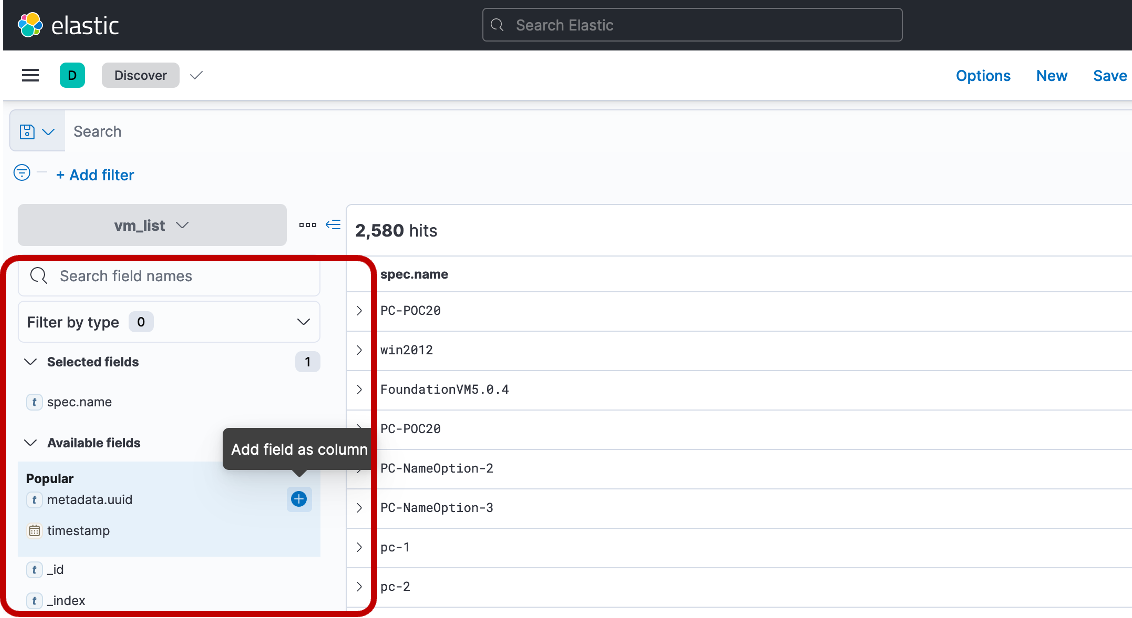
これで、Kibana上で VM名 と uuid だけが表示されるので

VM名 とかで検索したらサクッと uuid が判明します
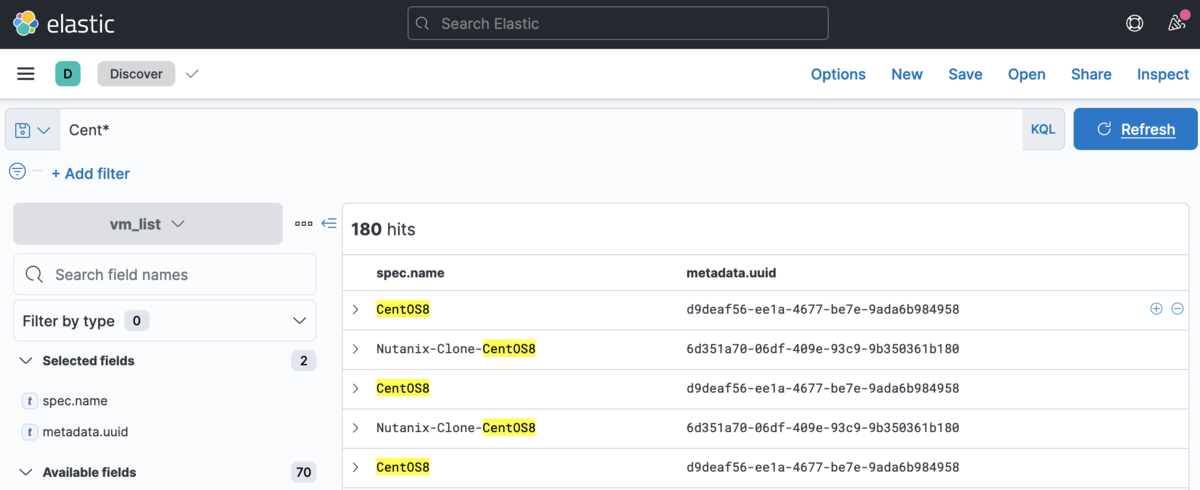
と、まぁこれだけだとたんなる Elasticsearch 講座に進んでしまいそうなので、ElasticsearchをDBのように使いつつ、ここからオリジナルGUIを自作していきたいと思います
次回は、Flask編につづく!