E資格向けの自習アウトプット
自分用メモ
確率的勾配降下法(SGD: Stochastic Gradient Descent)は、ミニバッチの単位で無作為に選んだデータで勾配降下法を使ってパラメータを更新していく方法

パラメータの更新方法は、誤差逆伝播で求めた勾配を使って各パラメータ(重み:w、バイアス:b)を更新する
誤差逆伝播で求めた勾配とハイパーパラメータで設定した学習率をつかって、現在のパラメータから算出する
重み(w)を更新する例
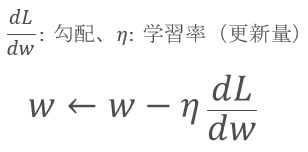
SGD は下記の条件で収束する

学習率は 0.01 や 0.001 あたり初期設定するが
・学習率が小さすぎると、学習が遅い
・学習率が大きすぎると、勾配が「0」になる地点にを通りこしてしまう
いずれにしてもいつまでたっても最適なパラメータにならないので、学習がうまくいく手動で調整していく
(最適な学習率を算出する方法もあるぽい)
# 確率的勾配降下法(SGD)でパラメータ更新 lr = 0.01 w1 = w1 - lr * dw1 b1 = b1 - lr * db1 w2 = w2 - lr * dw2 b2 = b2 - lr * db2
ここまでのステップをミニバッチの単位で、順伝播、誤差逆伝播、パラメータ更新を入力データ分一回回すことをエポックという
ミニバッチは、128や256くらいが多い
エポックは、1000回とか
入力データは1個だけ適当な入力データで、エポック 10回分まとめてみた
SGD で Loss が 減っていくはず
初期値の運が悪いと変わらないこともある
Epoch 0 loss: 0.5865723008185625 Epoch 1 loss: 0.13462761604484846 Epoch 2 loss: 0.06494275759481465 Epoch 3 loss: 0.043350135099269806 Epoch 4 loss: 0.03267105727966781 Epoch 5 loss: 0.026833979478593808 Epoch 6 loss: 0.023582050848936328 Epoch 7 loss: 0.020985603880502638 Epoch 8 loss: 0.018869993146677137 Epoch 9 loss: 0.017116506612223987